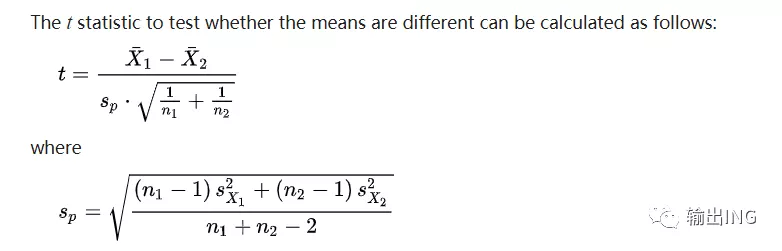《人类简史》这本书近几年挺热的,之前一直想读却没能开始。好在近2个月Jeff 的阅读习惯逐渐培养,又赶上2019新年开始,于是决定从这本书开始今年的阅读旅程。
一、该书的基本信息
豆瓣链接:《人类简史》
阅读耗时:16小时
评分:4颗星(总分5颗星)
导读:腾讯视频节目《一本好书》 第4期:王自健趣味解读《人类简史》,人类这样主宰地球
二、该书的基本内容
这本书讲述了人类从远古采集社会历经认知革命、农业革命、科学革命和工业革命直到现代的过程。
很多人说读完这本书的反应是颠覆了一些认知,因为里边很多观点跟我们从小学习到觉得理所当然的完全不同。比如说,我们觉得因为人类大脑足够发达能够思考,手脚足够灵活能制作和使用工具,所以最终人类能够统治和主宰地球。
但作者并不这么认为,相反,人类大脑很发达对应就需要脑容量很大,从而使得脑袋很大,这样会导致直立的人类容易背痛、脖颈僵硬。另外,不止是人类能制作和使用工具,其他人种比如尼安德特人也可以,而且他们身材更加魁梧,打猎技巧高明,但最终还是没留存下来。
作者的观点是,人类之所以可以战胜远古时期各种巨型动物和其他人种而独霸全球,在于人类学会了使用火,更重要的是人类有高级语言,可以相互沟通交流;人类能创造虚构故事,从而可以形成信任,进而具备大规模协作组织的能力。
三、阅读后的收获
坦白说,我读完这本书时并没有认知颠覆的感觉。这可能是当时并不是抱持特定目的去读这本书的,当然更重要的是,对人类之所以能够主宰全球的原因,之前也缺乏了解和深入思考。所以作者在书中表达他的观点时,自然很容易就接受了。
总的来说,这本书让我较系统地了解了人类发展史,也获得了一些新知。获得的新知包括智人迁徙、宗教信仰、殖民以及濒危物种等话题。
历史上,智人从欧亚非大陆迁徙到大洋洲、美洲等都造成了当地很多大型动物惨遭灭绝。这个可能是人类迁徙来后,因为生产生活引起了当地生态环境急剧变化,一些大型动物难以适应如此快速的变化所致。
关于宗教信仰
宗教信仰从崇拜所属及多少,可大致分为泛神论、多神论、二元论论、一神论、自然法则论。远古时期的宗教信仰多属于泛神论,除了有动物的神还有非生物的神,比如石神、水神;多神论如印度教,信奉很多神,如创造之神梵天、毁灭之神湿婆、维护之神毗湿奴;二元论比如摩尼教,认为存在善神和恶神;一神论比如犹太教、基督教、伊斯兰教,分别信奉唯一的真神耶和华、耶和华(或雅威)、安拉;自然法则论如佛教,核心人物释迦牟尼是人不是神,相信世间所有神、人、动物、植物都受到自然法则的约束。
关于殖民
欧洲各国向外殖民扩张时期,成立了一些特许公司,上市发行股票,通过股票募集的资金来支持向外扩张所需雇佣兵、船只、炮弹等费用。然后等到占领了当地,就开始倾销商品,或者控制当地政府提高税费,从而掠夺当地财富。
关于物种灭绝
由于人类的过度开发,越来越多的动植物在减少甚至濒临灭绝。一些我们常在电视看到的动物,也所剩不多了。比如,地球上的黑猩猩只剩25万只,狼只剩20万只,长颈鹿不足8万只。
四、一点反思
- 之后要尽量避免不具目的的阅读;
- 在保持不太慢阅读速度的同时,更要保证阅读的质量,阅读过程中可尝试质疑、联想,争取跟已有认知产生更多联结,从而激发更多思考。