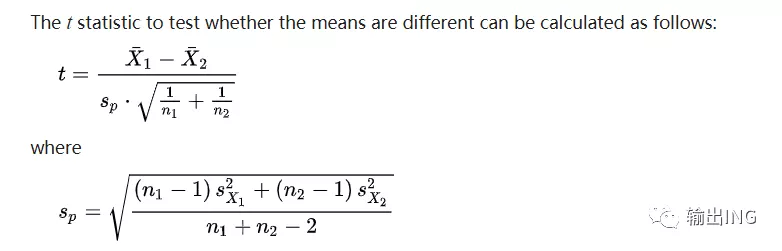注:2024.11.11 更新样本量计算公式
以后文章更新会先在微信公众号(公众号名:输出ING),欢迎大家来关注。
本文暂不介绍实验所需样本量公式的由来,而是先给出样本量计算常用的几个公式,以及在Excel、R、Python等工具中实现实验样本量计算的方法。
A/B 测试一般是比较实验组和对照组在某些指标上是否存在差异,当然更多时候是看实验组相比对照组某个指标表现是否更好。
这样的对比在统计学上叫做两样本假设检验,即实验组和对照组为两样本,假设检验的原假设Ho:实验组和对照组无显著差异;备择假设H1:实验组和对照组存在显著差异。
显然,如果实验选取的样本很小,实验结果可信度就不高,因为很可能抽取的样本不能代表真实的水平。而在实际中,因为各种成本的考量,实验样本量也不可能无限大。那么,一般至少需要多少样本才能得到可信的结论呢?
实验所需样本量的一般公式
统计学里有最小样本量计算的公式,公式如下:
 样本量计算公式
样本量计算公式
其中n是每组所需样本量,因为A/B测试一般至少2组,所以实验所需样本量为2n;α和β分别称为第一类错误概率和第二类错误概率,一般分别取0.05和0.2;Z为正态分布的分位数函数;Δ为两组数值的差异,如点击率1%到1.5%,那么Δ就是0.5%;σ为标准差,是数值波动性的衡量,σ越大表示数值波动越厉害。
从这个公式可以知道,在其他条件不变的情况下,如果实验两组数值差异越大或者数值的波动性越小,所需要的样本量就越小。
比例类数值所需样本量的计算
实际A/B测试中,我们关注的较多的一类是比例类的数值,如点击率、转化率、留存率等。
这类比例类数值的特点是,对于某一个用户(样本中的每一个样本点)其结果只有两种,“成功”或“未成功”;对于整体来说,其数值为结果是“成功”的用户数所占比例。如转化率,对于某个用户只有成功转化或未成功转化。
比例类数值的假设检验在统计学中叫做两样本比例假设检验。其最小样本量计算的公式为:
Read More →