以后文章更新会先在微信公众号(公众号名:输出ING),欢迎大家来关注。

一、实验效果不显著怎么办
为了使A/B实验得到统计显著的结果,有三个思路:
- 上线对指标影响较大的策略,然而多数情况下这种策略可遇而不可求;
- 增加实验的样本量,应该是普遍用的最多的,可通过提高实验流量配比或者让实验持续更长时间来实现;
- 缩减指标的方差,根据前面样本量计算和显著性检验介绍的公式可以知道,指标方差越小,所需样本量越小,也越容易统计显著;
微软2013年发表过一篇论文(本文阅读原文点击可直达该论文pdf),介绍了一种利用实验前的数据来缩减指标方差,进而提高实验灵敏度的方法,这种方法就是本文要介绍的CUPED(Controlled-experiment Using Pre-Experiment Data)。
二、CUPED简介
2.1 CUPED思路
CUPED的核心思路是构造了一个新的指标,假定实验原来观测的指标为Y,新的指标为Ycv(cv表示control variable),且将Ycv定义如下:

2.2 CUPED特性
构造出来的Ycv有很好的特性,一是Ycv的均值是我们实验关注的指标Y的无偏估计,二是Ycv的方差小于原来指标的方差。如果能选取跟Y高度相关的协变量X,那么Ycv的方差相比Y将会小很多。

2.3 使用CUPED时需要注意的点
2.3.1 协变量X的选择非常关键
因为Var(Ycv)=Var(Y)*(1-ρ^2),而ρ是X和Y的相关系数。也就是说如果能找到一个跟Y最相关的变量X,那么Ycv的方差最小,从而方差缩减效果最明显。
根据论文作者所述,多数时候最相关的还是原来这个指标,比如实验要比较的是时长的差异,即Y为实验的时长数据,那么X就选实验用户在实验前的时长数据。实验前数据应该选取多长周期呢,一般选一周到两周就够了。注意这里X和Y都是向量,即实验中每个用户在实验前的时长和实验时的时长。
2.3.2 实验前数据如果没有的解决办法
因为实验中可能有新用户,或者用户活跃频次原因,实验中的用户在实验前不一定都能找到对应数据。
这种情况下该怎么处理呢?微软论文提到可以再引入一个二元协变量,来表示该用户是否在实验前所选周期内出现了。不过Booking.com用的是另一个处理方法,是采用实验前指标的均值来填充那些在实验前所选周期未出现用户的指标的值。
2.3.3 不止于实验前数据
协变量的数据不止可以用实验前数据,也可以用实验期间的数据,只是一定要保证所选的这个变量不会受实验策略的影响。比如用户首次进入实验的所属当天星期几就可以作为一个协变量。
另外,任何在实验策略效果生效前的实验期间的数据都满足不受实验策略影响的限制,因此都可以作为协变量,尤其是实验策略生效比例极低的情况下,这些数据用来做协变量可能会很有用。
2.3.4 非用户级别指标的处理方法
因为前面假设实验的基本单元和指标计算的基本单元是用户,如果实验指标的计算单元更细,比如CTR,那么需要delta method和方差缩减一起使用。这时候协变量也就不止限于用户级别数据了,更细粒度如页面级别也是可以的。
三、CUPED在业界的应用
微软
微软Bing在研究页面加载时长对CTR影响的实验中,使用常规的未做方差削减的t-test,实验到第2周末的时候才看到统计显著的结果;而采用CUPED削减方差后,实验开始后第1天就得到统计显著的结果。
同样这个实验,采用CUPED只用一半的样本量就可以达到跟常规未做方差削减的t-test一样的效果,即进行到实验第2周末的时候得到统计显著的结果,相比常规未做方差削减的检验节省了一半的样本量。

Booking
Booking在研究新加的日历功能是否会带来收益时,采用常规未做方差削减的检验,实验跑了6周才得到统计显著的结果;而采用CUPED方差削减后,实验第1周之后就统计显著了。
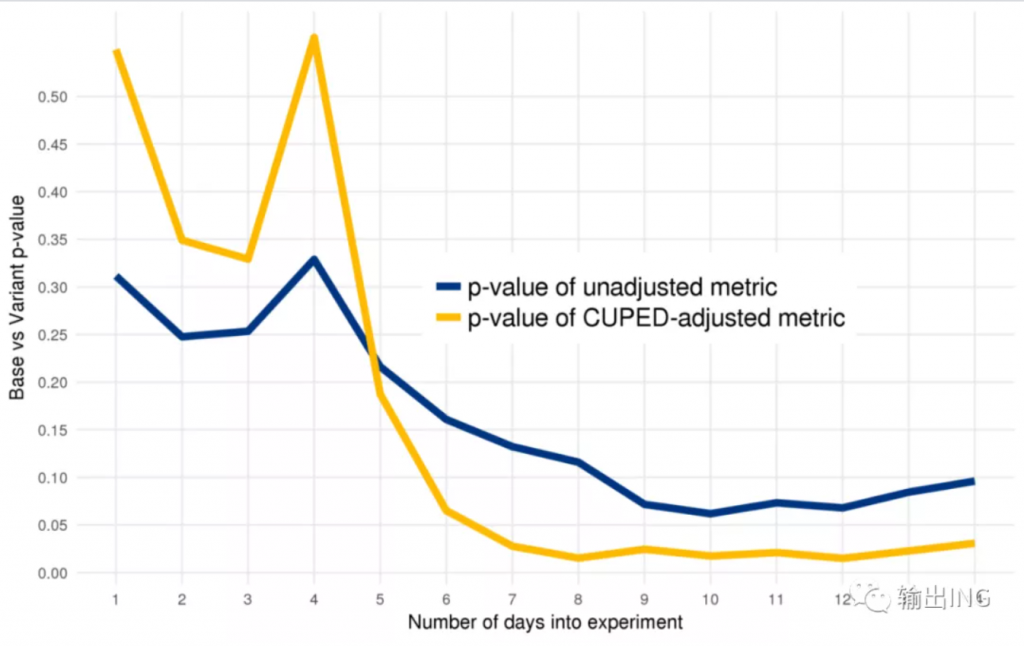
除了上面提到的微软、Booking有在应用CUPED,根据公开资料,Netflix、Uber、TripAdvisor等公司也在应用CUPED方法。
四、总结
提高实验的灵敏度是实验领域一个重要的课题,而其中一种很重要的方式就是削减方差。
如果实验足够灵敏,我们就更容易发现那些微小正向提升的实验,而不至于因为指标方差过大而被判别为统计功效不足、统计不显著;也能及时制止那些略微负向,但因为指标方差过大而被认为负向不显著的实验全量上线。对于大用户量的在线实验来说,一点点微小的正向提升或负向作用的影响可能都非常大。
CUPED是一种新的适用于在线实验的方差削减方法,其足够简洁易用,实验平台默认不支持的情况下,在Hive中也能较容易实现。值得一提的是,微软实际在使用CUPED时,校正指标Ycv=Y-θ*X,X为协变量,这里Booking和微软不一样。
五、参考资料
1. 微软论文 https://exp-platform.com/Documents/2013-02-CUPED-ImprovingSensitivityOfControlledExperiments.pdf
2. Netflix论文 https://www.kdd.org/kdd2016/papers/files/adp0945-xieA.pdf
3. Booking博客 https://booking.ai/how-booking-com-increases-the-power-of-online-experiments-with-cuped-995d186fff1d
4. TripAdvisor博客 https://www.tripadvisor.com/engineering/reducing-a-b-test-measurement-variance-by-30/
5. Uber博客 https://eng.uber.com/xp/
6. 博客园风雨中的小七的博客 https://www.cnblogs.com/gogoSandy/p/11749262.html
(说明:本文涉及图片版本均归原作者所有)
更敏感是否意味着假阳性也会增加?
理论上一个统计量一天只产出一个样本,第一天怎么能计算显著度呢
不会,一天1万用户,就是1万样本量啊
每天一万用户,那两天的样本量是1万还是2万呢?
严谨地说,是两天排重。但通常计算时不会那么严谨,尤其是某些特殊场景下,比如新用户,多天可以认为可直接累加作为总的样本量。
这里修正下,在标准的实验分析里,就是应该多天排重来统计
如果一天1万用户,就是1万样本量的话,这一万样本量的指标大概率不服从正态分布,指标会有很多极端值,怎么直接进行假设检验呢
这一万用户可以看做总体的抽样分布,然后根据中心极限定理,不管原始分布如何,抽样分布都可以作为正态分布来处理。