最近一个同学找到我,希望我帮忙处理一份数据。那份数据是这样的:包含了3661行,第一行为各列的名称;包含8列,第一列为专利ID,其余7列为企业ID。
这份数据截图如下所示:
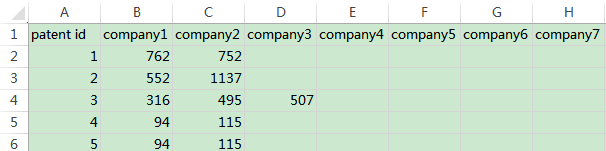
一、问题描述
需要做的数据处理是,求所有专利之间的关系矩阵,这里的关系指的是:当同一个企业同时申请了两个不同的专利,那么就认为这两个专利是有关系的。也就是说,当两个专利对应的企业的集合存在交集,则认为这两个专利存在关系。需要用矩阵表达这3660个专利的相互关系,有关系的两个专利交叉的位置置为1,否则置为0。
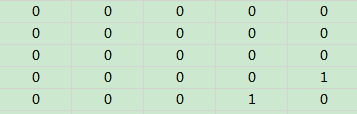
比如,上图中的编号4和编号5对应的企业的集合显然存在交集(交集为94和115),那么最终的关系矩阵第四行第五列和第五行第四列就应当用1表示。如果数据就是上边那样的,那么最终输出的关系矩阵就应该为:
二、问题解决
可能因为有段时间没有使用R了,加上之前又正好在用awk, grep, bash这些,所以一直想使用这些工具来解决。不过,想了很久,依然进展不大(主要是许久不用大多也忘了o(╯□╰)o)。后来看到压在桌面上的《R语言实战》,想到这里需要的输出是矩阵,而且主要的逻辑判定为是否有交集,这些不正是R大展拳脚的地方吗?!
于是先用伪代码将整个逻辑梳理了一遍,然后照着伪代码开始写R脚本。由于逻辑并不复杂,所以很快便写好了,代码如下:
data <- read.csv("C:\\Users\\dell\\Desktop\\data.csv") #读取数据
relation_matrix <- matrix(0, 3660, 3660) #创建一个与源数据行数相等的方阵,所有元素初始化为0
for (i in 1:3660)
for (j in 1:3660) {
company_set1 = data[i, -1][!is.na(data[i, -1])] #读取第i个专利对应的企业编号集合
company_set2 = data[j, -1][!is.na(data[j, -1])] #读取第j个专利对应的企业编号集合#如果第i个专利和第j个专利对应的企业有相同的,则将对应位置置为1
if (i != j && length(intersect(company_set1, company_set2)) > 0)
relation_matrix[i, j] = 1
}write.csv(relation_matrix, "C:\\Users\\dell\\Desktop\\result.csv") #将关系矩阵写到文件中
代码是很快写好了,不过执行速度确慢得难以忍受。无奈,找了个办法来缓解下焦急等待程序跑完的心情。到统计之都找到一个用在循环里显示进度条的程序改了改,终于好点了,也大概能算出来程序什么时候能跑完了。
包含显示进度条的程序代码如下:
data <- read.csv("C:\\Users\\dell\\Desktop\\data.csv") #读取数据
relation_matrix <- matrix(0, 3660, 3660) #创建一个与源数据行数相等的方阵,所有元素初始化为0
#创建进度条
pb <- txtProgressBar(min = 0, max = 3660, style = 3)for (i in 1:3660)
for (j in 1:3660) {
company_set1 = data[i, -1][!is.na(data[i, -1])] #读取第i个专利对应的企业编号集合
company_set2 = data[j, -1][!is.na(data[j, -1])] #读取第j个专利对应的企业编号集合#如果第i个专利和第j个专利对应的企业有相同的,则将对应位置置为1
if (i != j && length(intersect(company_set1, company_set2)) > 0)
relation_matrix[i, j] = 1#设置进度条
Sys.sleep(0.00001)
setTxtProgressBar(pb, i)
}write.csv(relation_matrix, "C:\\Users\\dell\\Desktop\\result.csv") #将关系矩阵写到文件中
显示效果如下所示:
![]()
三、解决优化
虽然比之前好些了,但还是没有解决程序运行缓慢等待时间过长的问题。毫无疑问,这段程序肯定还有很大的优化空间,于是先读取少量的数据,试着使用Rprof分析了一下耗时情况,结果发现[.data.frame 这个操作的耗时占比较大,Google搜索后在这里找到了一个优化的方法,即对源数据读取到到data frame之后再拷贝到一个矩阵中做取行的值的操作。优化后的版本:
data <- read.csv("C:\\Users\\dell\\Desktop\\data.csv") #读取数据
relation_matrix <- matrix(0, 3660, 3660) #创建一个与源数据行数相等的方阵,所有元素初始化为0
data_matrix <- data.matrix(data_test[, -1]) #将数据拷贝到一个矩阵中#创建进度条
#pb <- txtProgressBar(min = 0, max = 3660, style = 3)for (i in 1:3660)
for (j in 1:3660) {
company_set1 = data_matrix[i, ][!is.na(data_matrix[i, ])] #读取第i个专利对应的企业编号集合
company_set2 = data_matrix[j, ][!is.na(data_matrix[j, ])] #读取第j个专利对应的企业编号集合#如果第i个专利和第j个专利对应的企业有相同的,则将对应位置置为1
if (i != j && length(intersect(company_set1, company_set2)) > 0)
relation_matrix[i, j] = 1#设置进度条
#Sys.sleep(0.00001)
#setTxtProgressBar(pb, i)
}write.csv(relation_matrix_test, "C:\\Users\\dell\\Desktop\\result.csv") #将关系矩阵写到文件中
在同样的机器环境下,改进后的程序只需要10min左右,而改进前的版本则需要将近7个小时,执行效率提高了40倍!
四、补充
在做这个数据处理过程中,值得记录的还包括:
- R语言程序多个语句的时候记得带上{},用缩进控制是Python的做法;
- 源数据读取之前要简单校验下,防止包含异常值影响数据读取的结果(这里包含了#REF!,处理很久才发现);
- 在Excel中比较两份格式完全一样的数据是否相同,复制其中一份选择性粘贴“减”操作到另一份数据,选择数据区域看右下角显示的总和是否为0即可。
- 本文相关参考链接:1)Help interpreting output of Rprof 2)How to efficiently use Rprof in R?
patent_id <- seq(1,3661,by=1)
comany1 <- round(runif(3661,1,3000))
comany2 <- round(runif(3661,1,3000))
comany3 <- round(runif(3661,1,3000))
comany4 <- round(runif(3661,1,3000))
comany5 <- round(runif(3661,1,3000))
comany6 <- round(runif(3661,1,3000))
comany7 <- round(runif(3661,1,3000))
data <- data.frame(patent_id, comany1, comany2, comany3, comany4, comany5, comany6, comany7)
library(reshape)
md <- melt( data, id =(c("patent_id")) )
md <-data.frame(md[,1],paste(md[,2],md[,3]) )
colnames(md)=c("patent_id","num")
ch<-data.frame( table(md$num) )
ch1),][,1]
ch<- as.character(ch) #除去因子
relation_matrix <- matrix(0, 3661, 3661)
pb <- txtProgressBar(min = 0, max = 3661, style = 3)
i<-1
while(i<(length(ch)+1) ){
x <-which(md$num==ch[i])
n<-1
while( n<length(x)){
relation_matrix[md[x[n],1],md[x[n+1],1]]<-1
n=n+1
}
rm(x,n)
i<-i+1
Sys.sleep(0.00001)
setTxtProgressBar(pb, i)
}
relation_matrix <-relation_matrix+t(relation_matrix)
write.csv(relation_matrix, "result.csv")
这位兄弟,我写R脚本不多,请问这句是什么意思呢?
ch< -data.frame( table(md$num) ) ch1),][,1]我也试了下,用最简单的循环就很快:
data_matrix<- matrix(as.integer(data.matrix(data[, -1])),ncol = 7)
system.time(
for (i in 1:3661){
a<-setdiff(data_matrix[i,],NA) #这步放这里可以减少重复,而且只要a里面没有NA即可
for (j in 1:i){
b<-data_matrix[j,]
relation_matrix[i,j]<-ifelse(sum(a %in% b),1,0)
}
}
)
用户 系统 流逝
49.41 0.05 50.53
(回复的话还是邮件,不一定会再来这个页面。)
看了你的您的文章,我也试了下,我自己写的代码,运行不到一分钟!我觉得还有更快的速度
patent_id <- seq(1,3661,by=1)
comany1 <- round(runif(3661,1,3000))
comany2 <- round(runif(3661,1,3000))
comany3 <- round(runif(3661,1,3000))
comany4 <- round(runif(3661,1,3000))
comany5 <- round(runif(3661,1,3000))
comany6 <- round(runif(3661,1,3000))
comany7 <- round(runif(3661,1,3000))
data <- data.frame(patent_id, comany1, comany2, comany3, comany4, comany5, comany6, comany7)
library(reshape)
md <- melt( data, id =(c("patent_id")) )
md <-data.frame(md[,1],paste(md[,2],md[,3]) )
colnames(md)=c("patent_id","num")
ch<-data.frame( table(md$num) )
ch1),][,1]
ch<- as.character(ch)
relation_matrix <- matrix(0, 3661, 3661)
pb <- txtProgressBar(min = 0, max = 3661, style = 3)
i<-1
while(i<(length(ch)+1) ){
x <-which(md$num==ch[i])
n<-1
while( n<length(x)){
relation_matrix[md[x[n],1],md[x[n+1],1]]<-1
n=n+1
}
rm(x,n)
i<-i+1
Sys.sleep(0.00001)
setTxtProgressBar(pb, i)
}
relation_matrix <-relation_matrix+t(relation_matrix)
write.csv(relation_matrix, "result.csv")