Python 的sklearn库包含许多可用于机器学习的工具,本文以经典的泰坦尼克号问题为例,来说明在Python中使用sklearn做机器学习的一般流程。由于本人对机器学习了解还不深,对于本文内容如有任何建议或意见,欢迎提出!闲话少说,咱们立即进入主题。
1. 读取并查看数据
泰坦尼克号问题,Kaggle上提供了较为详细的数据说明和下载地址,本文这里不再赘述。有需要了解的同学请移步这里。
首先,我们导入需要用到的库文件,为之后工作做准备:
# 导入后续需要用到的库文件 import numpy as np import pandas as pd import seaborn as sns import matplotlib.pylab as plt from sklearn.preprocessing import StandardScaler from sklearn.cross_validation import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report
然后读取数据并查看:
# 读取数据并查看
data = pd.read_csv("train.csv")
data.head()
可以看到数据长这样的:
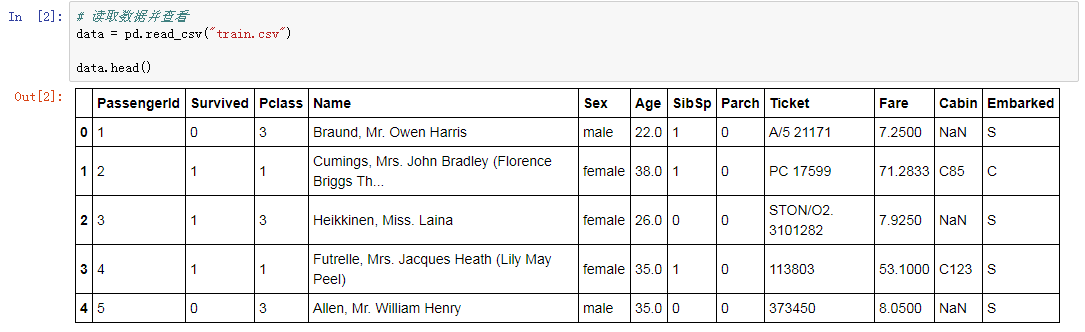
查看数据行和列:
# 查看数据行列 data.shape
输出:(891, 12)
说明有891行,12列。
查看缺失值的情况:
# 检查NA值的情况 data.isnull().sum()
得到:

可以看到Age, Cabin, Embarked这三列均存在缺失值,其中Cabin列缺失很严重。不过这列表示船舱号,直观上我们觉得这个跟最终是否能幸存关系不大,所以缺失就缺失吧。
2. 特征选取
泰坦尼克号这个数据集中,有乘客ID、是否存活、船票等级、乘客姓名、乘客性别、年龄、船上兄弟姊妹或配偶个数、床上父母或子女个数、船票号码、船票价格、船舱号、上船港口等数据。
显然,是否存活是我们将要预测的量,而乘客ID、乘客姓名、船票号码、船舱号,我们觉得跟最终是否能存活关系不大,于是忽略它们,剩余其他的列作为后续模型训练的特征。
选取特征并查看选取后的数据:
# 选取数据集中有用的特征 data = data.drop(labels=['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1) data.head()
运行后可以看到: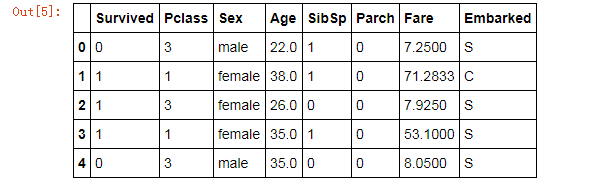 我们后面建模用来训练的数据将会来自于这里。
我们后面建模用来训练的数据将会来自于这里。
3. 缺失值处理
前面我们看到,原数据中有不少缺失值,这里我们选最简单的缺失值处理办法,即将包含缺失值的行全部舍弃:
# 去除有缺失值的行 data = data.dropna()
4. 离散特征处理
上边留下来的列,Pclass表示船票等级,为有序分类变量,已经是数值型;Sex和Embarked为无序分类变量,为字符型;Age、SibSp、Parch、Fare为连续变量。
sklearn中模型最后训练的数据需要是数值型的,因此Sex和Embarked这两列的数值需要转换为数值型。
我们直接用pandas中的get_dummies即可对无序分类变量进行编码:
# 分类变量编码 data_dummy = pd.get_dummies(data[['Sex', 'Embarked']])
编码后与原来其他列的数据重新拼接起来:
# 编码后和原来其他列数据拼接
data_conti = pd.DataFrame(data, columns=['Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare'], index=data.index) data = data_conti.join(data_dummy)
5. 分割训练集和测试集
数据集基本行列都确定之后,我们就可以进行分割了,这里将30%的数据集作为测试集:
X = data.iloc[:, 1:] y = data.iloc[:, 0] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
6. 连续特征处理
要保证模型训练时快速收敛,我们需要对数据集中连续的数据列进行缩放,这里使用标准化的方法:
# 标准化 stdsc = StandardScaler() X_train_conti_std = stdsc.fit_transform(X_train[['Age', 'SibSp', 'Parch', 'Fare']]) X_test_conti_std = stdsc.fit_transform(X_test[['Age', 'SibSp', 'Parch', 'Fare']]) # 将ndarray转为dataframe X_train_conti_std = pd.DataFrame(data=X_train_conti_std, columns=['Age', 'SibSp', 'Parch', 'Fare'], index=X_train.index) X_test_conti_std = pd.DataFrame(data=X_test_conti_std, columns=['Age', 'SibSp', 'Parch', 'Fare'], index=X_test.index)
最后我们将处理好的数据列再次拼接起来,用于接下来模型的训练:
# 有序分类变量Pclass X_train_cat = X_train[['Pclass']] X_test_cat = X_test[['Pclass']] # 无序已编码的分类变量 X_train_dummy = X_train[['Sex_female', 'Sex_male', 'Embarked_C', 'Embarked_Q', 'Embarked_S']] X_test_dummy = X_test[['Sex_female', 'Sex_male', 'Embarked_C', 'Embarked_Q', 'Embarked_S']] # 拼接为dataframe X_train_set = [X_train_cat, X_train_conti_std, X_train_dummy] X_test_set = [X_test_cat, X_test_conti_std, X_test_dummy] X_train = pd.concat(X_train_set, axis=1) X_test = pd.concat(X_test_set, axis=1)
7. 建模和预测
使用sklearn中逻辑回归模型进行训练并做预测:
# 基于训练集使用逻辑回归建模 classifier = LogisticRegression(random_state=0) classifier.fit(X_train, y_train) # 将模型应用于测试集并查看混淆矩阵 y_pred = classifier.predict(X_test) confusion_matrix = confusion_matrix(y_test, y_pred) print(confusion_matrix)
查看模型的准确率:
# 在测试集上的准确率
print('Accuracy of logistic regression classifier on test set: {:.2f}'.format(classifier.score(X_test, y_test)))
运行后得到:
Accuracy of logistic regression classifier on test set: 0.77
查看模型的性能指标:
print(classification_report(y_test, y_pred))
运行后得到:
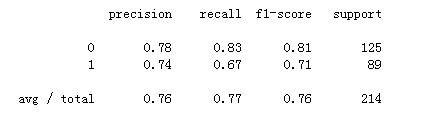
至此,基于逻辑回归来预测泰坦尼克号乘客存活基本就完成了。但是这个模型准确率仅76%,还有优化空间。比如这里特征选取比较主观,模型训练时也直接用的默认参数,没有调参使模型更优。此外,机器学习中分类有关的算法很多,比如支持向量机、决策树、随机森林、朴素贝叶斯等,逻辑回归并不一定最适合这个问题。
因此,我们将在之后尝试对这个模型进行优化,以使模型预测准确率更高一些。